Windowing and Analytics Functions
- 开窗分析函数
- Hive QL 的增强功能
- 样例
- PARTITION BY 带一个分区列,没有ORDER BY或开窗规范
- PARTITION BY 带两个分区列,没有ORDER BY或开窗规范
- PARTITION BY 带一个分区列,一个ORDER BY列,无开窗规范
- PARTITION BY 带两个分区列,两个ORDER BY列,无开窗规范
- PARTITION BY 带分区列,ORDER BY,开窗规范
- WINDOWS字句
- LEAD使用默认的1行导联,而不指定默认值
- LAG指定3行的滞后,默认值为0
- DISTINCT为每个分区计数
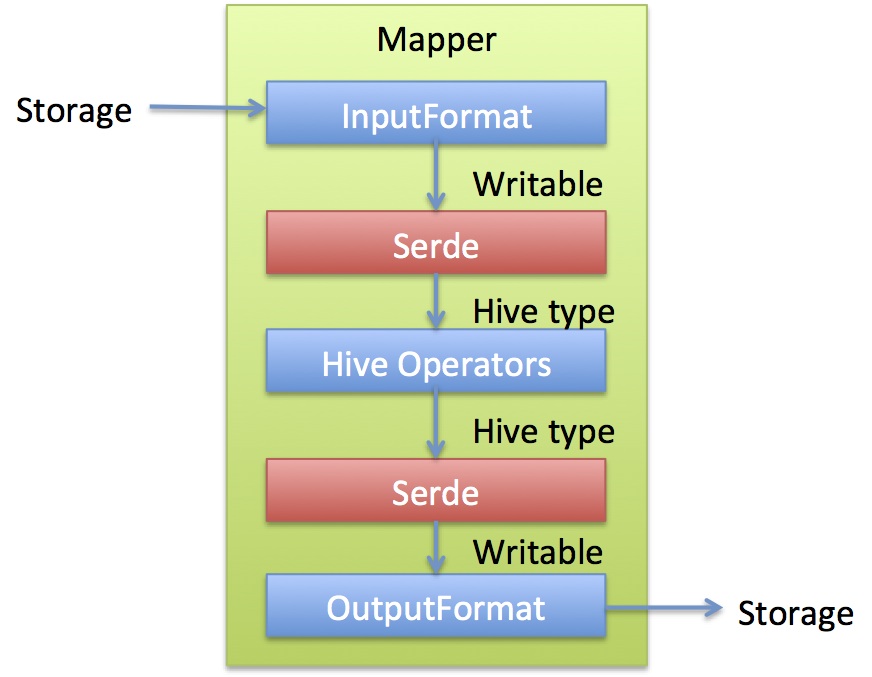
HiveQL 的增强功能
版本:
介绍Hive版本0.11
这个部分介绍Hive增强的开窗分析函数, 查看HQL的窗口规范详情,HIVE-896 有更详细的信息,包括最初意见中的文档链接。
所有的开窗分析函数功能都是按照SQL标准来使用
当前版本支持以下开窗分析函数:
- 开窗函数
- LEAD
- 可以可选地指定要引导的行数。 如果未指定要引导的行数,则引导为一行
- 当当前行的引线超出窗口末尾时返回null
- LAG
- 可以选择指定要延迟的行数。 如果未指定要延迟的行数,则延迟为一行
- 当当前行的延迟在窗口开始之前延伸时返回null
- FIRST_VALUE
- LAST_VALUE
- LEAD
OVER 字句
- OVER与标准的聚合
- COUNT
- SUM
- MIN
- MAX
- AVG
- OVER中的PARTITION BY子句使用一个或多个任何基本数据类型的分区列
OVER中的PARTITION BY和ORDER BY字句使用任何数据类型的一个或多个分区和/或排序列
OVER有一定的窗口规范,窗口可以在WINDOW子句中单独定义。 窗口规范支持这些标准选项:
ROWS ((CURRENT ROW) | (UNBOUNDED | [num]) PRECEDING) AND (UNBOUNDED | [num]) FOLLOWINGOVER子句支持以下功能,但它不支持带有它们的窗口(参见[HIVE-4797](https://issues.apache.org/jira/browse/HIVE-4797)): 排名函数:Rank,NTile,DenseRank,CumeDist,PercentRank。 LEAD和LAG 函数。
- OVER与标准的聚合
- 分析函数
- RANK
- ROW_NUMBER
- DENSE_RANK
- CUME_DIST
- PERCENT_RANK
- NTILE
Hive 2.1.0 及更高版本支持DISTINCT (查看HIVE-9534)
DISTINCT支持SUM,COUNT和AVG等聚合函数,以及在每个分区内不同值上的聚合。
当前实现具有以下限制:由于性能原因,在分区子句中不能支持ORDER BY或窗口规范。 支持的语法如下:COUNT(DISTINCT a) OVER (PARTITION BY c)Hive 2.1.0 及更高版本支持聚合函数在OVER字句中使用
添加了对引用OVER子句中的聚合函数的支持。 例如,目前我们可以使用OVER子句中的SUM聚合函数,如下所示:SELECT rank() OVER (ORDER BY sum(b)) FROM T GROUP BY a;
样例
本节提供了如何在SELECT语句中使用Hive QL窗口化和分析函数的示例,更多的例子见HIVE-896
PARTITION BY 带一个分区列,没有ORDER BY或开窗规范
SELECT a, COUNT(b) OVER (PARTITION BY c)
FROM T;
PARTITION BY 带两个分区列,没有ORDER BY或开窗规范
SELECT a, COUNT(b) OVER (PARTITION BY c, d)
FROM T;
PARTITION BY 带一个分区列,一个ORDER BY列,无开窗规范
SELECT a, SUM(b) OVER (PARTITION BY c ORDER BY d)
FROM T;
PARTITION BY 带两个分区列,两个ORDER BY列,无开窗规范
SELECT a, SUM(b) OVER (PARTITION BY c, d ORDER BY e, f)
FROM T;
PARTITION BY 带分区列,ORDER BY,开窗规范
SELECT a, SUM(b) OVER (PARTITION BY c ORDER BY d ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
FROM T;
SELECT a, AVG(b) OVER (PARTITION BY c ORDER BY d ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
FROM T;
SELECT a, AVG(b) OVER (PARTITION BY c ORDER BY d ROWS BETWEEN 3 PRECEDING AND 3 FOLLOWING)
FROM T;
SELECT a, AVG(b) OVER (PARTITION BY c ORDER BY d ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
FROM T;
在单个查询中可以有多个OVER子句。 单个OVER子句仅适用于前一个函数调用。 在此示例中,第一个OVER子句适用于COUNT(b),第二个OVER子句适用于SUM(b):
SELECT
a,
COUNT(b) OVER (PARTITION BY c),
SUM(b) OVER (PARTITION BY c)
FROM T;
也可以使用别名,带或不带关键字AS:
SELECT
a,
COUNT(b) OVER (PARTITION BY c) AS b_count,
SUM(b) OVER (PARTITION BY c) b_sum
FROM T;
WINDOWS字句
SELECT a, SUM(b) OVER w
FROM T
WINDOW w AS (PARTITION BY c ORDER BY d ROWS UNBOUNDED PRECEDING);
LEAD使用默认的1行导联,而不指定默认值
SELECT a, LEAD(a) OVER (PARTITION BY b ORDER BY C ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING)
FROM T;
LAG指定3行的滞后,默认值为0
SELECT a, LAG(a, 3, 0) OVER (PARTITION BY b ORDER BY C ROWS 3 PRECEDING)
FROM T;
DISTINCT为每个分区计数
SELECT a, COUNT(distinct a) OVER (PARTITION BY b)
FROM T;