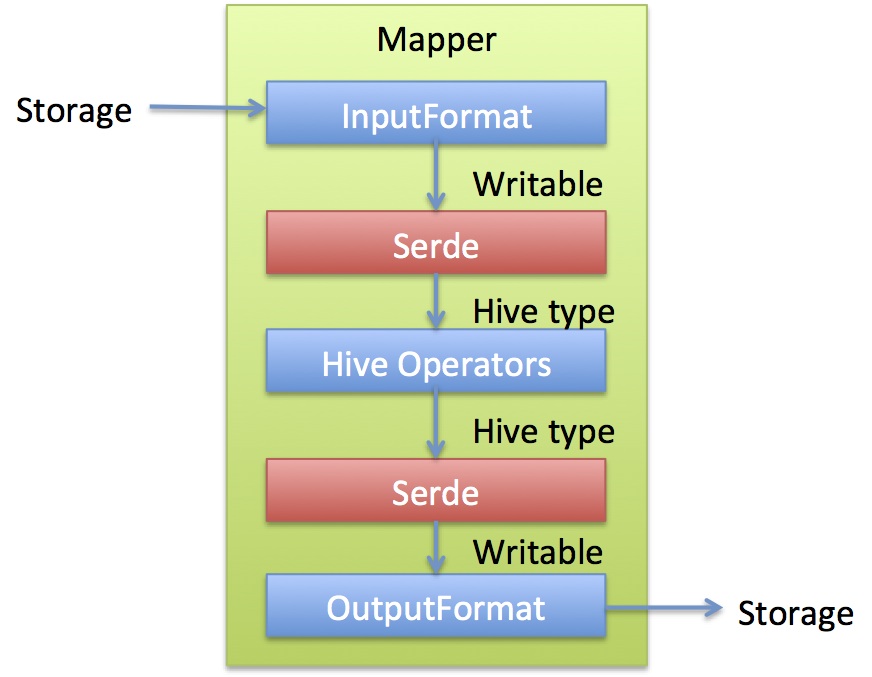
针对一定规则的HDFS文件,为了更好地和Hive表结合,定制HiveInputFormat
查看GitHub项目, 需要实现包含如下:
- FileInputFormat
- RecordReader
- SerDe
- HiveStorageHandler
FileInputFormat
定义MyFileInputFormat 继承 FileInputFormat(旧接口 org.apache.hadoop.mapred)该类没有做任何其它操作,仅仅只是重写了getRecordReader方法
public class MyHiveInputFormat extends FileInputFormat<Text, BytesWritable> {
@Override
public RecordReader<Text, BytesWritable> getRecordReader(InputSplit split, JobConf job, Reporter reporter)
throws IOException {
// TODO Auto-generated method stub
return new MyHiveRecordReader(split, job);
}
}
RecordReader — MapReduce 重要组件
- 以怎样的方式从分片中读取一条记录,每读取一条记录都会调用RecordReader类
- 默认的RecordReader是LineRecordReader,如TextInputFormat
- LineRecordReader是用每行的偏移量作为map的key,每行的内容作为map的value
- 读入数据主要处理逻辑在
next方法中
public class MyHiveRecordReader implements RecordReader<Text, BytesWritable> {
private static final Log LOG = LogFactory.getLog(MyHiveRecordReader.class);
private long start;
private long pos;
private long end;
private InputStream in;
public MyHiveRecordReader(InputSplit genericSplit, Configuration conf) throws IOException {
FileSplit split = (FileSplit) genericSplit;
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
FileSystem fs = file.getFileSystem(conf);
FSDataInputStream fileIn = fs.open(file);
CompressionCodecFactory compressionCodecFactory = new CompressionCodecFactory(conf);
final CompressionCodec codec = compressionCodecFactory.getCodec(file);
if (codec != null) {
LOG.debug("use conf compressioncodec.");
in = codec.createInputStream(fileIn);
} else {
in = new SnappyInputStream(fileIn);
}
pos = start;
}
public boolean next(Text key, BytesWritable value) throws IOException {
byte[] header = new byte[4];
while (in.read(header, 0, 4) != -1) {
int bodyLength = bytesToInt(header);
byte[] body = new byte[bodyLength];
in.read(body, 0, bodyLength);
key.set(new Text());
value.set(body, 0, bodyLength);
return true;
}
return false;
}
public Text createKey() {
return new Text();
}
public BytesWritable createValue() {
return new BytesWritable();
}
public long getPos() throws IOException {
return this.pos;
}
public float getProgress() throws IOException {
if (start == end) {
return 0.0f;
} else {
return Math.min(1.0f, (pos - start) / (float) (end - start));
}
}
public void close() throws IOException {
if (in != null) {
in.close();
}
}
// bytes 高位存储转int
private int bytesToInt(byte[] bits) {
int val;
val = (int) ((bits[3] & 0xFF)
| ((bits[2] & 0xFF) << 8)
| ((bits[1] & 0xFF) << 16)
| ((bits[0] & 0xFF) << 24));
return val;
}
}
SerDe
Hive的反序列化是对key/value反序列化成hive table的每个列的值。SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化
public class MyHiveSerDe implements SerDe {
private StructObjectInspector objectInspector;
private List<String> columnNames;
private List<Object> row;
private int numColumns;
private List<PrimitiveCategory> columnTypes;
private static final Logger LOG = LoggerFactory.getLogger(MyHiveSerDe.class);
public void initialize(Configuration conf, Properties tbl) throws SerDeException {
// TODO Auto-generated method stub
LOG.debug("Initializing WTableHiveSerDe");
// Get column names and types
String columnNameProperty = tbl.getProperty(serdeConstants.LIST_COLUMNS);
String columnTypeProperty = tbl.getProperty(serdeConstants.LIST_COLUMN_TYPES);
// all table column names
if (columnNameProperty.length() == 0) {
columnNames = new ArrayList<String>();
} else {
columnNames = Arrays.asList(columnNameProperty.split(","));
}
numColumns = columnNames.size();
String[] hiveColumnTypes = columnTypeProperty.split(":");
// all column types
List<ObjectInspector> fieldInspectors = new ArrayList<ObjectInspector>(numColumns);
columnTypes = new ArrayList<PrimitiveCategory>(numColumns);
for (int i = 0; i < numColumns; i++) {
String typeName = hiveColumnTypes[i];
PrimitiveCategory type = null;
try {
type = PrimitiveObjectInspectorUtils.getTypeEntryFromTypeName(typeName).primitiveCategory;
columnTypes.add(type);
} catch (Exception e) {
throw new SerDeException(typeName + " is not supported!");
}
fieldInspectors.add(PrimitiveObjectInspectorFactory.getPrimitiveJavaObjectInspector(type));
}
LOG.debug("columns: {}, {}", columnNameProperty, columnNames);
LOG.debug("types: {}, {} ", columnTypeProperty, columnTypes);
assert (columnNames.size() == columnTypes.size());
row = new ArrayList<Object>(numColumns);
objectInspector = ObjectInspectorFactory.getStandardStructObjectInspector(columnNames, fieldInspectors);
}
public Object deserialize(Writable blob) throws SerDeException {
// TODO Auto-generated method stub
BytesWritable writable = (BytesWritable) blob;
CommonDump commonDump = null;
try {
commonDump = CommonDump.parseFrom(writable.copyBytes());
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
return null;
}
Map<FieldDescriptor, Object> _fields = commonDump.getAllFields();
Map<String, Object> fields = new HashMap<String, Object>(_fields.size());
row.clear();
Iterator<FieldDescriptor> fieldKeys = _fields.keySet().iterator();
while (fieldKeys.hasNext()) {
FieldDescriptor fieldKey = fieldKeys.next();
fields.put(fieldKey.getName().toLowerCase(), _fields.get(fieldKey));
}
for (int i = 0; i < numColumns; i++) {
String colName = columnNames.get(i).toLowerCase();
row.add(optVal(columnTypes.get(i), fields.get(colName)));
}
return row;
}
public ObjectInspector getObjectInspector() throws SerDeException {
// TODO Auto-generated method stub
return objectInspector;
}
public SerDeStats getSerDeStats() {
// TODO Auto-generated method stub
return new SerDeStats();
}
public Class<? extends Writable> getSerializedClass() {
// TODO Auto-generated method stub
return MyWritable.class;
}
public Writable serialize(Object obj, ObjectInspector objInspector) throws SerDeException {
// TODO Auto-generated method stub
throw new SerDeException("Serialize to db does not supported. Pull-request is appreciated.");
}
public static final Object optVal(PrimitiveCategory pcat, Object val) {
switch (pcat) {
case INT:
return Integer.valueOf(String.valueOf(val));
case LONG:
return Long.valueOf(String.valueOf(val));
case BINARY:
return ((ByteString) val).toByteArray();
case STRING:
default:
return new String(((ByteString) val).toByteArray());
}
}
}
HiveStorageHandler
使用HiveStorageHandler 整合InputFormat、OutputFormat、SerDe
public class MyStorageHandler implements HiveStorageHandler {
private Configuration conf;
public void setConf(Configuration conf) {
this.conf = conf;
}
public Configuration getConf() {
return this.conf;
}
@SuppressWarnings("rawtypes")
public Class<? extends InputFormat> getInputFormatClass() {
return MyHiveInputFormat.class;
}
@SuppressWarnings("rawtypes")
public Class<? extends OutputFormat> getOutputFormatClass() {
return HiveIgnoreKeyTextOutputFormat.class;
}
public Class<? extends SerDe> getSerDeClass() {
return MyHiveSerDe.class;
}
public HiveMetaHook getMetaHook() {
return null;
}
public HiveAuthorizationProvider getAuthorizationProvider() throws HiveException {
return null;
}
public void configureInputJobProperties(TableDesc tableDesc, Map<String, String> jobProperties) {
// TODO Auto-generated method stub
}
public void configureOutputJobProperties(TableDesc tableDesc, Map<String, String> jobProperties) {
// TODO Auto-generated method stub
}
public void configureTableJobProperties(TableDesc tableDesc, Map<String, String> jobProperties) {
// TODO Auto-generated method stub
}
public void configureJobConf(TableDesc tableDesc, JobConf jobConf) {
// TODO Auto-generated method stub
}
}
总结
定制HiveInputFormat可灵活让Hive与HDFS文件结合, 重点掌握FileInputFormat,如果考虑到小文件,可使用CombineFileInputFormat